Excel tabular exports
The Excel tabular export is an export type that is used in many exporting and importing functionalities of AseptSoft.
Followed by:
The tabular export produces tables of data on each row of a document.
One export will produce a hierarchy of elements which organises the data:
More Excel Workbooks (files)
Each Excel Workbook (file) contains more rows (Pages)
Each Worksheet (page) contains a single table
Each table contains a header, a dominant column, and a set of cells where each corresponds to a row-column pair.
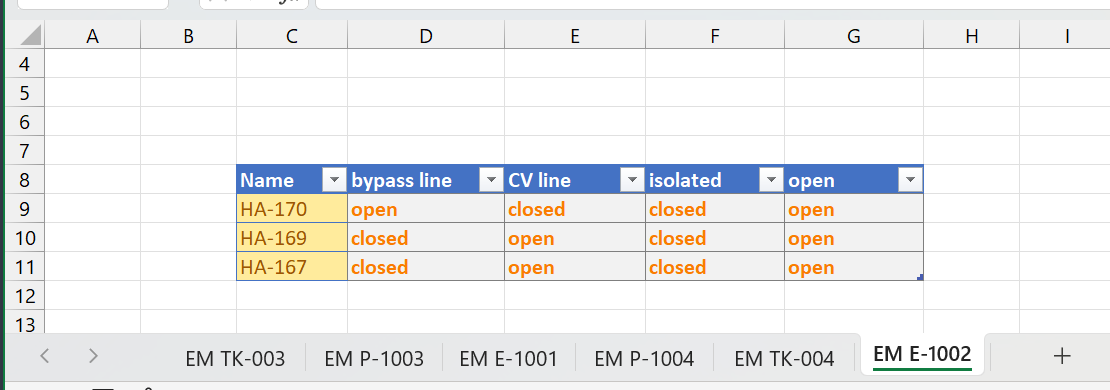
Example Workbook with more Worksheets, each containing one table
Format Identification Rules
In order for the table to be recognised and updated, the worksheet must have empty cells above the table on any column.
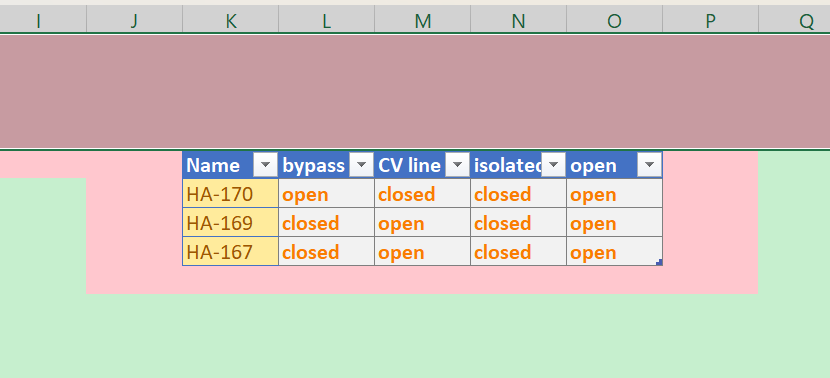
On the left side of the header there should only be empty cells on any column.
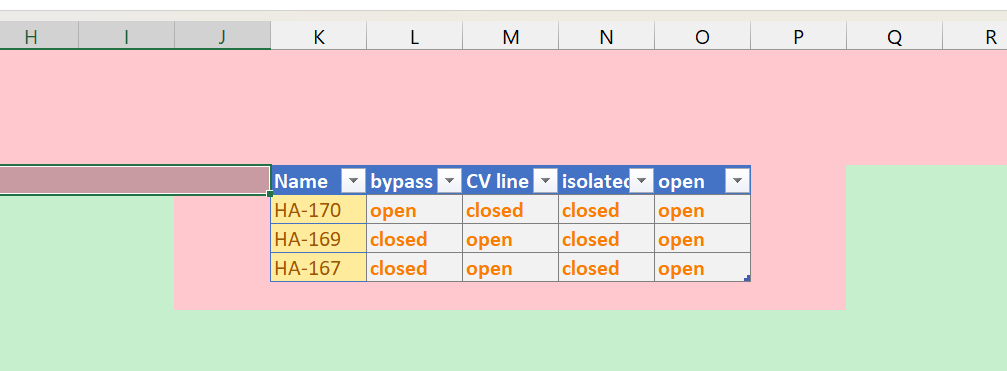
At the border with the table there should only be empty cells

Anywhere else there can be any text:

The table header must have unique values in each cell. In the example before “Name”, “bypass line”, “CV line”, “isolated”, “open” are different. AseptSoft ensures this rule before the export.
There is a single dominant column which does not need to be the first one, but AseptSoft will always make it first at the first export. When you reorder the columns, depending on which export it is, AseptSoft will preserve the order you choose. In the example before “Name” is the name of the dominant column.
The values of the cells in this column must be unique. AseptSoft ensures this.The dominant column is used by AseptSoft to identify row positions. As this export format is a cumulative export, AseptSoft assumes that the user might have reordered the rows since the last export. To match the newly to be exported rows with the existing ones, AseptSoft will use the value of each row on the dominant column. In the example above, “HA-170”, “HA-169”, “HA-167” will be used to match with the data to update with.
If the data to update with does not perfectly match, for example a new valve is introduced “HA-1”, whilst the old “HA-170” is missing from the new data, then the entire “HA-170” row will be deleted, and the last row of the table “HA-167” will be duplicated below and updated with the values of the new “HA-1”.
Format Update Rules
When an existing file is about to be updated with new data, the Table identification process is first performed for the old data to be extracted. Then a matching process is performed, old data will be split into data to remove, data to update, and data to add. The matching follows some rules, and individual tabular exports will use different options. Here we describe the behaviour based on the options:
Workbook deletion option: Workbooks are matched by name. If in the destination folder there is a Workbook with a name that can not be found in the data to export, then choose to delete it.
Worksheet Creation option: Worksheets are matched by name. If a worksheet with the required name does not exist, and the document is fresh (i.e. it has just been created) then the required worksheet will be created. If the document is not Fresh (i.e. it existed from an older update, and we are in an update scenario) then the Worksheet Creation option will be followed.
Worksheet Reorder option: If the existing worksheets order does not match the order in which the new data would align them, choose to update the order rather than keeping the old one.
Worksheet Deletion option: If a worksheet exists, but there is no data which match it, choose to delete it.
Column Creation option: Columns are matched by name. If a column with the required name does not exist, and the document is fresh (i.e. it has just been created) then the required column will be created. If the document is not Fresh (i.e. it existed from an older update, and we are in an update scenario) then the Column Creation option will be followed.
Column Reorder option: If the existing Columns order does not match the order in which the new data would align them, choose to update the order rather than keeping the old one.
Column Deletion option: If a Column exists, but there is no data which match it, choose to delete it.
Row Creation option: rows are matched by name. If a row with the required name does not exist, and the document is fresh (i.e. it has just been created) then the required row will be created. If the document is not Fresh (i.e. it existed from an older update, and we are in an update scenario) then the row Creation option will be followed.
Row Reorder option: If the existing rows order does not match the order in which the new data would align them, choose to update the order rather than keeping the old one.
Row Deletion option: If a row exists, but there is no data which match it, choose to delete it.